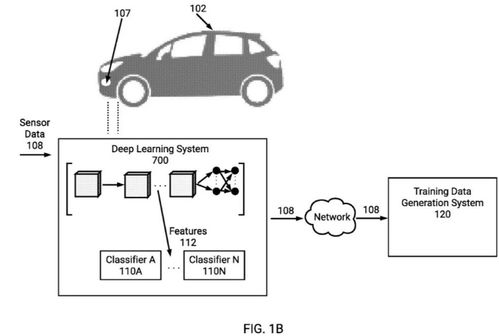
特斯拉向美國專利商標局提交的一項新專利,再次成為科技與汽車行業矚目的焦點。該專利的核心,是提出了一種從龐大的消費者車隊中高效獲取數據,并用以訓練其自動駕駛神經網絡的方法。這不僅揭示了特斯拉在自動駕駛技術開發上的獨特路徑,也預示著一場關于數據驅動、算法迭代的技術革命正在加速。
專利的核心:讓每輛特斯拉都成為“數據采集員”與“學習節點”
這項名為“從車隊數據中自動識別用于神經網絡訓練的事件”的專利,其精髓在于自動化與規模化。特斯拉的車輛在道路上行駛時,其搭載的傳感器(攝像頭、雷達等)會持續收集海量的真實世界數據。專利描述的系統能夠自動分析這些數據流,智能識別出對自動駕駛算法訓練有特殊價值的“事件”或場景片段。
例如,系統可以自動篩選出復雜的交叉路口處理、罕見的極端天氣駕駛、行人與非機動車的突然出現、施工區域繞行等傳統測試難以窮盡的“長尾場景”。這些寶貴的真實世界片段被自動標記、匿名化處理后,匯入特斯拉龐大的數據中心,成為其自動駕駛神經網絡(尤其是負責感知和決策的神經網絡)持續進化的“養料”。
數據閉環:特斯拉難以復制的核心壁壘
這項專利背后,體現的是特斯拉構建的“數據閉環”生態。與許多依賴模擬仿真或有限路測的競爭對手不同,特斯拉通過已售出的數百萬輛汽車,建立了一個全球范圍內、7x24小時不間斷運行的龐大數據采集網絡。每一輛在路上行駛的特斯拉,都是一個動態的數據源。
- 規模優勢:特斯拉全球車隊的規模是任何一家競爭對手短期內難以企及的。這意味著它能接觸到更多樣化、更復雜的駕駛場景,尤其是那些發生概率極低但至關重要的“邊緣案例”。
- 真實世界價值:從真實用戶日常駕駛中獲取的數據,遠比封閉測試場或模擬環境中的數據更具現實復雜性和訓練價值。這能讓神經網絡學習到人類駕駛員在實際中如何處理各種模糊和意外情況。
- 持續迭代能力:通過專利中描述的自動化數據篩選和訓練流程,特斯拉可以近乎實時地將新遇到的道路場景納入神經網絡的訓練集,從而推動其全自動駕駛(FSD)系統以更快的速度進化,實現“越用越聰明”。
技術挑戰與隱私考量
這條技術路徑也伴隨著挑戰。從 petabytes 級別的海量數據中高效、準確地自動識別有價值片段,本身就需要極其強大的邊緣計算和云端數據處理能力。數據的匿名化處理、傳輸安全以及用戶隱私保護是重中之重。特斯拉在專利和其政策中均強調,所有用于訓練的數據都將經過嚴格的匿名化處理,剝離任何與車輛或個人身份相關的信息,僅保留純粹的駕駛場景數據。如何平衡技術創新與隱私保護,將是其持續面臨的公眾審視。
行業影響:重塑自動駕駛開發范式
特斯拉的這一專利策略,進一步鞏固了其“以數據驅動為核心”的自動駕駛開發范式。它表明,未來自動駕駛技術的競爭,不僅僅是算法和芯片的競爭,更是數據規模、數據質量以及數據利用效率的競爭。能否構建一個能夠低成本、自動化收集和利用真實世界數據的閉環系統,可能成為決定勝負的關鍵。
對于整個汽車產業而言,特斯拉的模式提供了另一種思路:將量產車變為研發的前沿哨所,讓消費者的日常使用直接參與技術的進化過程。這可能會加速自動駕駛技術從實驗室走向普及的進程,同時也可能引發關于數據所有權、技術倫理和行業標準的新一輪討論。
特斯拉申請的這一專利,遠不止是一項具體的技術方案,更是其宏大戰略的一塊關鍵拼圖。它彰顯了特斯拉將硬件(車輛)、軟件(算法)與數據(車隊)深度整合,以創造持續自我改進的自動駕駛系統的雄心。在通往全自動駕駛的道路上,特斯拉正試圖通過其獨一無二的車隊數據海洋,為其神經網絡注入對真實世界最深刻的理解,而這或許正是它試圖駛向未來的核心引擎。